
Optimización de políticas con señales intrínsecas densas
Descubre cómo ISPO usa señales intrínsecas densas para superar fallos en el razonamiento de modelos de lenguaje y mejorar su precisión.
Descubre cómo ISPO usa señales intrínsecas densas para superar fallos en el razonamiento de modelos de lenguaje y mejorar su precisión.
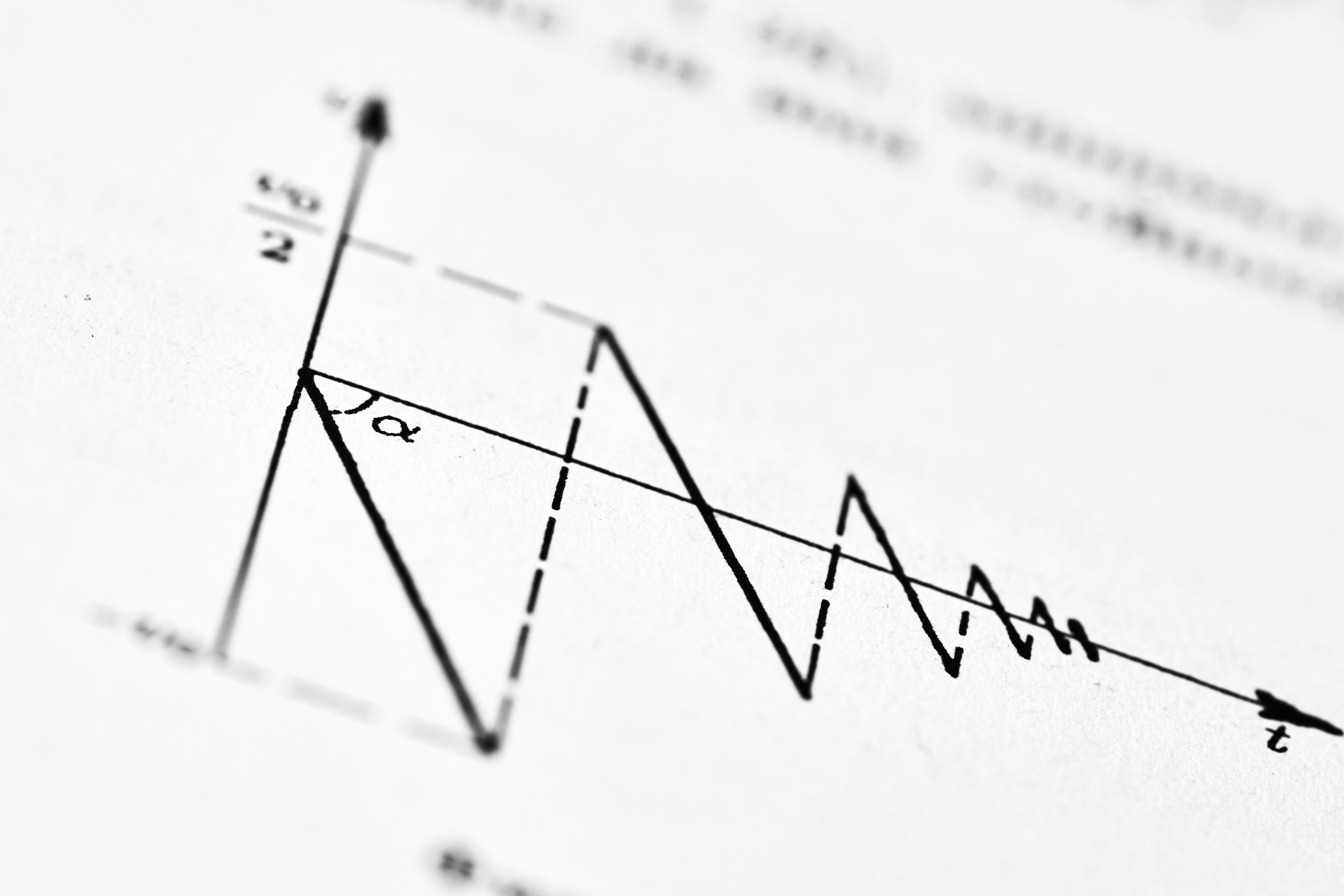
Descubre cómo ISPO mejora el razonamiento en LLMs con señales intrínsecas, superando fallos de GRPO como colapso y certeza alucinada.